开发语言
qt
动作识别
web3
lcd
办公软件
Molecular
turtle
蔚来
Hudi
NPDP认证
产品经理培训
系统架构
cisp证书
OpenHarmony
PEFT
溯源
acquireQueued
Sonar
可视化
预训练
2024/4/11 20:33:14
白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…

deepspeed多机多卡并行训练指南
文章目录 前言离线配置训练环境共享文件系统多台服务器之间配置互相免密登录pdsh多卡训练可能会碰到的问题注意总结 前言
我的配置:
7机14卡,每台服务器两张A800
问:为啥每台机只挂两张卡? 答:给我的就这样的&#…

AI大模型的预训练、迁移和中间件编程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…
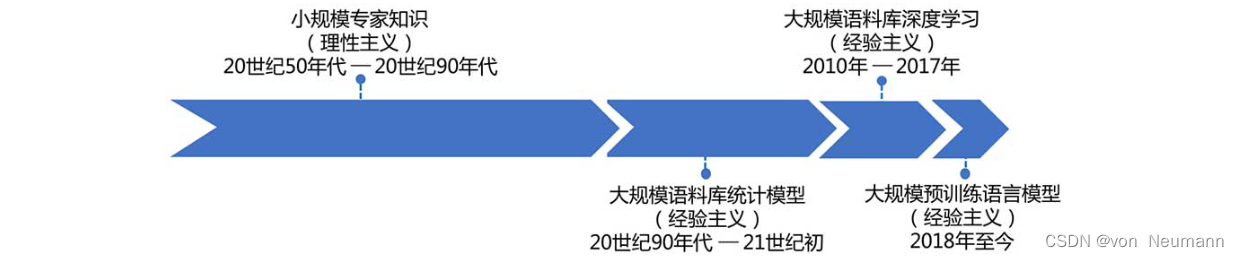
自然语言处理从入门到应用——自然语言处理(Natural Language Processing,NLP)基础知识
分类目录:《自然语言处理从入门到应用》总目录 自然语言通常指的是人类语言,是人类思维的载体和交流的基本工具,也是人类区别于动物的根本标志,更是人类智能发展的外在体现形式之一。自然语言处理(Natural Language Pr…

自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍 语言模型的历史演进大语言模型基础知识预训练Pre-traning微调Fine-Tuning指令微调Instruction Tuning对齐微调Alignment Tuning 提示Prompt上下文学习In-context Learning思维链Chain-of-thought提示开发(调用ChatGPT的…

从零开始训练一个ChatGPT大模型(低资源,1B3)
macrogpt-prertrain
大模型全量预训练(1b3), 多卡deepspeed/单卡adafactor
源码地址:https://github.com/yongzhuo/MacroGPT-Pretrain.git
踩坑
1. 数据类型fp16不太行, 很容易就Nan了, 最好是fp32, tf32,
2. 单卡如果显存不够, 可以用优化器adafactor,
3. 如果…
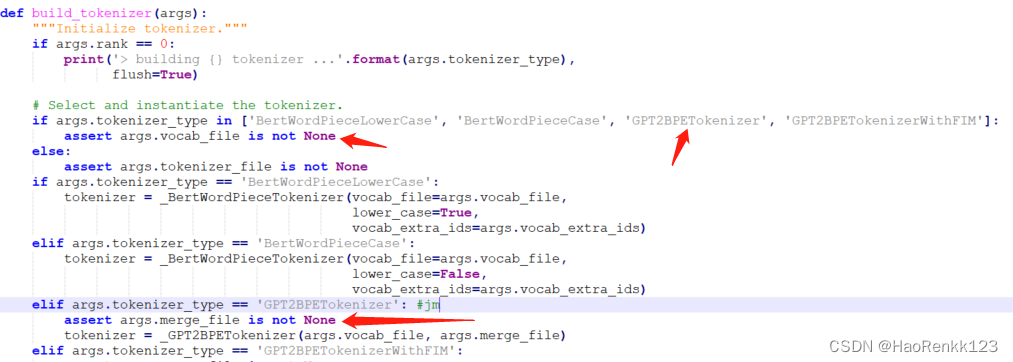
MegatronLM源码阅读-数据预处理
数据处理入口:
python tools/preprocess_data.py \--input content.jsonl \--output-prefix wudaocorpus_01 \--vocab ../starcoder/vocab.json \--dataset-impl mmap \--tokenizer-type GPT2BPETokenizer \--merge-file ../starcoder/merges.txt \--json-keys content \--wo…

文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks 1. 内容简介2. 模型结构 1. 数据处理2. 模型结构设计3. 模型训练 3. 实验结果 1. 图文联合任务 1. Visual Question Answering (VQA)2. Visual Reasoning3. Imag…
服务器配置Huggingface并git clone模型和文件
服务器配置Huggingface并git clone模型和文件
参考:https://huggingface.co/welcome
1 注册hugging face
官网注册,并获取token【https://huggingface.co/settings/tokens】,用于登录
2 安装
2.1 安装lfs
https://stackoverflow.com/qu…
NLP 自古以来的各预训练模型 (PTMs) 和预训练任务小结
😄目前写了预训练模型与任务的大致分类,还未将具体原理总结。持续更新ing。 ⏰ 早期的PTMs在模型结构上做的尝试比较多,transformers出现后,研究者们研究的重点就从模型结构转移到了训练任务与策略上。 ⭐ PTMSs优势在于: 1、大量的无标注数据进行预训练,降低人工标注成…

【AI视野·今日NLP 自然语言处理论文速览 第五十三期】Thu, 12 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 12 Oct 2023 Totally 69 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Proces…
关于神经网络预训练的讨论
简单来说,预训练模型(pre-trained model)是前人为了解决类似问题所创造出来的模型。你在解决问题的时候,不用从零开始训练一个新模型,可以从在类似问题中训练过的模型入手。比如说,如果你想做一辆自动驾驶汽车,可以花数…
基于GPT的隐变量表征解码结构
有时候我们想要用GPT(的一部分)作为预训练的隐变量解码器,应该怎么办呢?最近看论文,总结了三种隐变量注入(code injection)的方式。
1. Cheng X , Xu W , Wang T , et al. Variational Semi-Supervised Aspect-Term…

精细微调技术在大型预训练模型优化中的应用
目录 前言1 Delta微调简介2 参数微调的有效性2.1 通用知识的激发2.2 高效的优化手段3 Delta微调的类别3.1 增量式微调3.2 指定式微调3.3 重参数化方法 4 统一不同微调方法4.1 整合多种微调方法4.2 动态调整微调策略4.3 超参数搜索和优化 结语 前言
随着大型预训练模型在自然语…
【语言模型】快速了解大模型中的13个重要概念
快速了解大模型中的13个重要概念 1. 自回归语言模型2. 自编码语言模型3. 排列语言模型4. CLIP5. DreamBooth6. LoRA7. 图像超分辨率8. TimeGrad9.Diffusion-LM10.多模态11.向量数据库12.检索增强生成(RAG)13. AI for Science13.1 SMCDiff13.2 CDVAE 预训…

自动驾驶高效预训练--降低落地成本的新思路(ReSimAD)
自动驾驶高效预训练--降低落地成本的新思路 1. 引言定义高效预训练 2. ReSimAD2.1引言2.2 主要贡献1.发布大规模ReSimAD数据2.ReSimAD pipeline 2.3 实验 上海人工智能实验室
1. 引言 高效的预训练,是大模型的第一步 大模型的两种能力
海量数据分布–未知场景泛化…
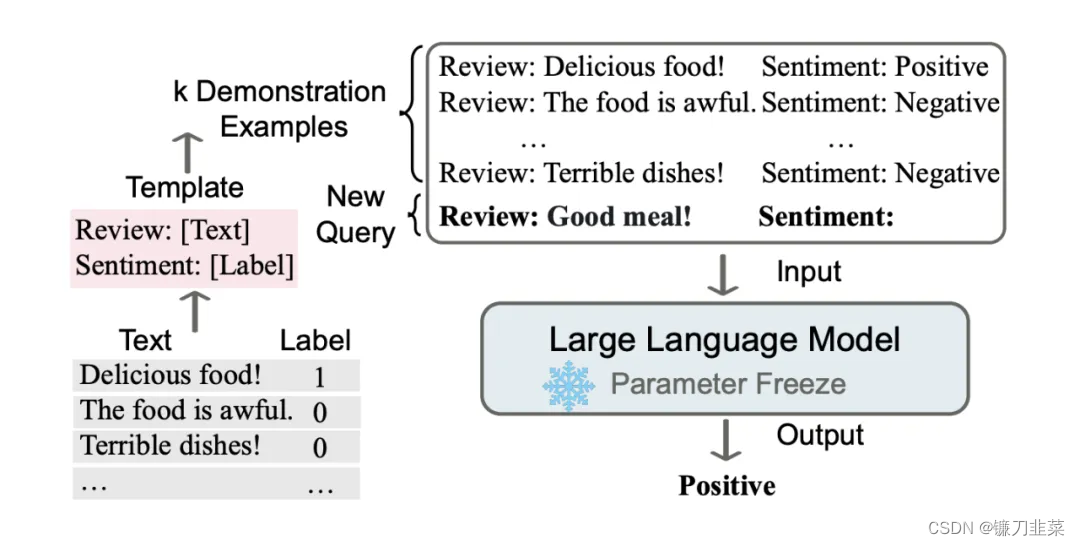
【大语言模型】5分钟了解预训练、微调和上下文学习
5分钟了解预训练、微调和上下文学习 什么是预训练?什么是微调?什么是上下文学习?相关资料 近年来大语言模型在自然语言理解和生成方面、多模态学习等方面取得了显著进展。这些模型通过
预训练、
微调和
上下文学习的组合来学习。本文将快速…

【论文解读】单目3D目标检测 DD3D(ICCV 2021)
本文分享单目3D目标检测,DD3D 模型的论文解读,了解它的设计思路,论文核心观点,模型结构,以及效果和性能。 一、DD3D简介
DD3D是一种端到端、单阶段的单目3D目标检测方法,它在训练时用到了点云数据…

基于LLMs的多模态大模型(MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP,X-LLM)
这个系列的前一些文章有:
基于LLMs的多模态大模型(Visual ChatGPT,PICa,MM-REACT,MAGIC)基于LLMs的多模态大模型(Flamingo, BLIP-2,KOSMOS-1,ScienceQA)
前…
推荐12篇预训练相关高分论文(附下载)
要问现在的论文圈“当红炸子鸡”是哪个?预训练模型肯定能上提名,作为科研热门方向,必然是不可忽略的。
所以今天一整理完就赶紧来和大家分享了,目前有十几篇预训练相关的高引论文,建议必读。后续有空的话会继续更新&a…
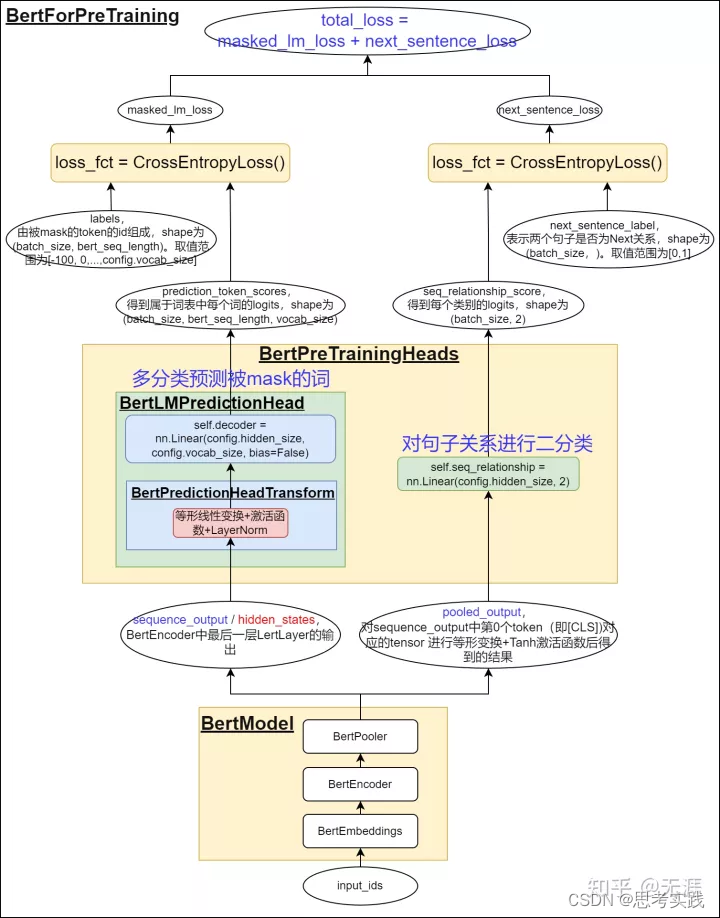
【LLM】预训练||两句话明白儿的底层原理
预训练鼻祖阶段:目前认为是Bert时期
从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的&#…
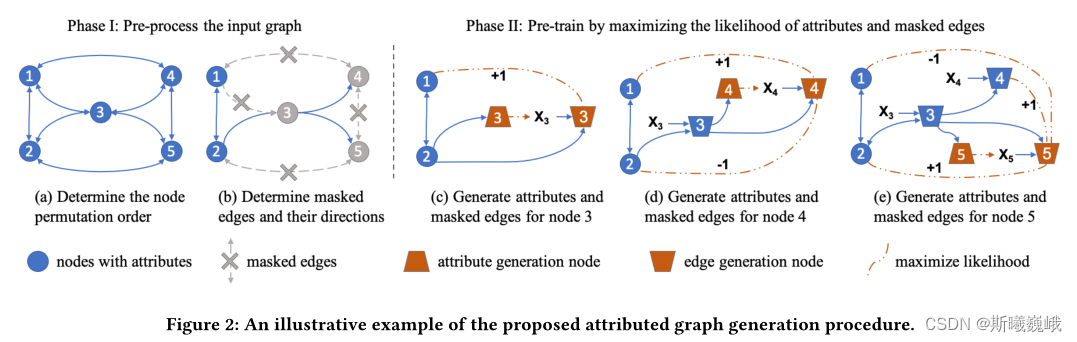
预训练GNN:GPT-GNN Generative Pre-Training of Graph Neural Networks
一.文章概述
本文提出了一种自监督属性图生成任务来预训练GNN,使得其能捕图的结构和语义属性。作者将图的生成分为两个部分:属性生成和边生成,即给定观测到的边,生成节点属性;给定观测到的边和生成的节点属性…
大模型+时空预测25篇高分论文分享,附开源数据集下载
面向时空数据的大模型是一类专门设计用于分析和挖掘时间序列和时空数据的复杂模型,它们不仅能够提高数据分析的效率和准确性,还能够在多个领域内发现有价值的信息,增强跨多个领域的模式识别和推理能力。
这次我就从大模型中的大语言模型LLMs…

BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法 FesianXu 20240202 at Baidu Search Team 前言
大规模语言模型(Large Language Model,LLM)是当前的当红炸子鸡,展现出了强大的逻辑推理,语义理解能力,而视觉作为人…

【AI视野·今日NLP 自然语言处理论文速览 第五十四期】Fri, 13 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 13 Oct 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models Authors Mengkang Hu, Yao M…

AlexNet Keras预训练模型
简介
因为Keras没有Alexnet预训练模型,我将Pytroch上的AlexNet预训练模型转成了Keras,供大家使用。因为AlexNet很简单,Keras和Pytroch代码都很容易理解,因此不做详细解释。
下载链接
链接: https://pan.baidu.com/s/1oAsVNANDd…
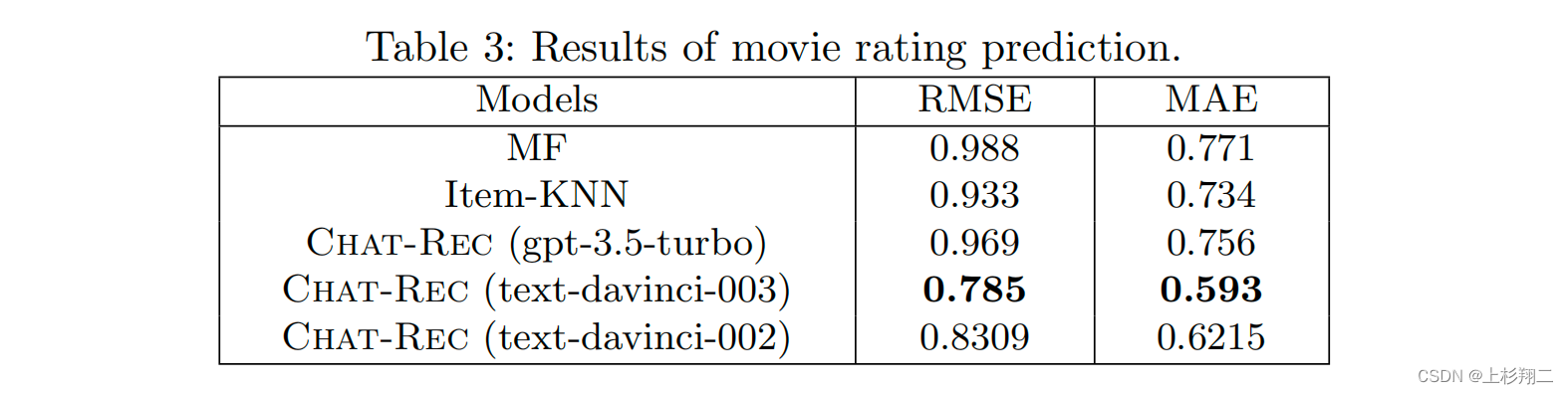
Chat-REC(LLM大模型用于推荐系统)
当众多chat-xxx和xxxGPT喷涌而出的时候,博主就在等它被做到推荐系统的这一天。本篇博文将简要看看一些文章的具体做法。
Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System 先上地址,
https://arxiv.org/abs/2303.145…
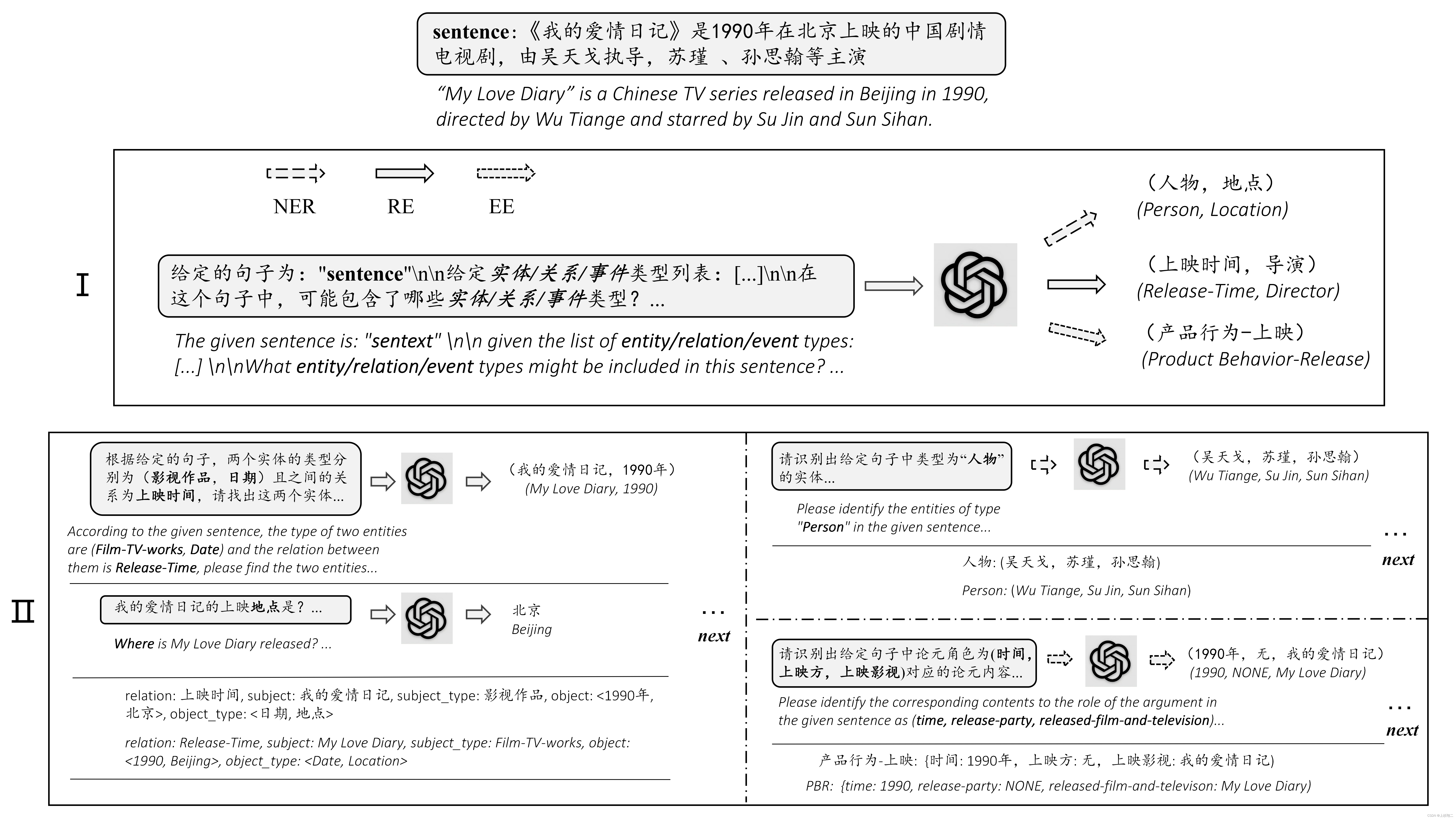
ChatIE(LLM大模型用于信息抽取)
Zero-Shot Information Extraction via Chatting with ChatGPT
paper:https://arxiv.org/abs/2302.10205
利用ChatGPT实现零样本信息抽取(Information Extraction,IE),看到零样本就能大概明白这篇文章将以ChatGPT作为…

自动驾驶高效预训练--降低落地成本的新思路(AD-PT)
自动驾驶高效预训练--降低落地成本的新思路 1. 之前的方法2. 主要工作——面向自动驾驶的点云预训练2.1. 数据准备 出发点:通过预训练的方式,可以利用大量无标注数据进一步提升3D检测 https://arxiv.org/pdf/2306.00612.pdf
1. 之前的方法
1.基于对比学…